莫名其妙被卡了好几天,然后突然想明白了,写篇题解。
题目链接。
题意
现在有 块蘑菇地,第 块蘑菇地初始有 个蘑菇,每天晚上一块地会长出 个蘑菇。
你每天早上可以选择一块地,并把这块地的所有蘑菇都拿走。
对每一个
求出,如果只有前
天早上你可以拿蘑菇,最多能拿多少。
。
题解
首先有一些比较简单的观察。
观察一:一块地不可能被采摘两次,因为如果被摘了两次,那么第一次采摘完全是可以省略掉的。
此时这一块地拿到的总蘑菇量不变,你还可以拿多出来这一天去采一块别的蘑菇地,稳赚不亏。
观察二:按照时间顺序,所有采摘的蘑菇地, 是递增的。
这个也很好理解,因为如果你已经确定了采集哪些蘑菇地,那么 的贡献就是确定的,你把
大的换到后面让他多长一些肯定更优。
那么这个时候就有一个
的暴力了。
首先将所有蘑菇地按照
升序进行排序,那么一定是先拿前面的再拿后面的。
设 表示从前 块蘑菇地里面,选出 块地,作为前 天采摘的目标,最多能有多少蘑菇。
转移比较简单,直接枚举第
块蘑菇地选不选就行。
转移方程是 。
那么考虑怎么优化这个东西呢,不妨想一想他有没有别的性质。
考虑相邻两天,采集蘑菇地的变化。
打个表或者自己瞎猜一下,都可以发现,第 天与第
天最优方案不同的地方,一定是恰好多采集了一块蘑菇地。
而不会出现,去掉
块蘑菇地,再添加
块蘑菇地这种情况。
为什么呢,假设
天的最优方案,少了
个蘑菇地而新添了
个蘑菇地(特殊的,如果有多个最优方案,选择 最小的那个):
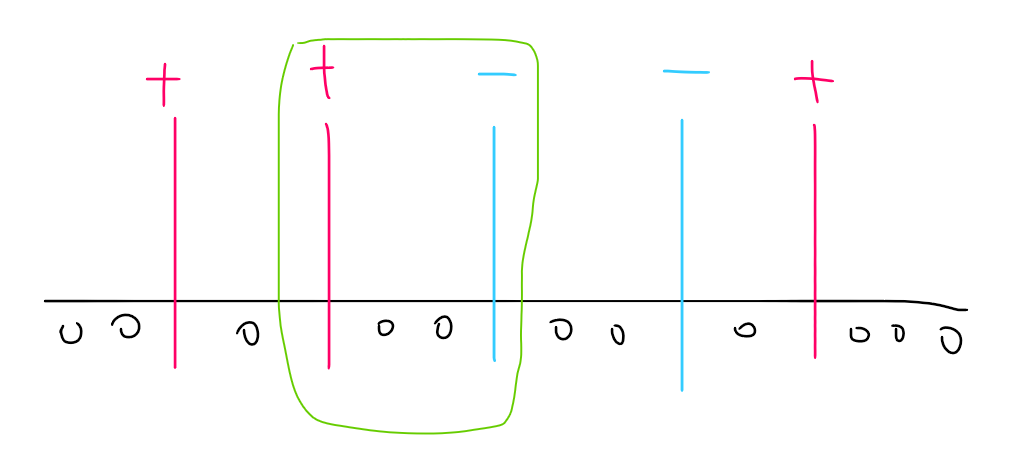
图中的
表示蘑菇地两天的状态相同,
表示只有后一天选中,
表示只有前一天选中。
若 ,那么一定可以找到一对
和 ,使得他们中间只有 ,比如图中的绿色框内两块蘑菇地。
考虑设当前的答案为 ,将这两块地有 变成 的方案答案设为 。
如果有 ,说明
天这个方案不是最优的,违背了我们的假设。
这说明有 ,这同样是矛盾的。
因为如果
这个方案更优,那么在第
天的时候,这两块地就应该是现在
这个状态了,这说明第
天的方案又不是最优的。
这样,我们使用了反证法,证明第 天恰好比第 天多选了一块蘑菇地。
那么这个时候我们又有一个
做法,对于每一天,直接枚举新选的蘑菇地是哪一块,然后选择增量最大的那个加入方案。
这是一个非常好的性质,再看一下之前的 dp 转移。
如果 ,这说明最优方案是不选
这块蘑菇地。
否则 ,这说明最优方案是选择 这块蘑菇地。
那么考虑我们刚刚的结论,可以发现一定存在一个 ,满足对于 的部分,最优方案是不选 ,而对于 的部分,最优方案是选择 。
那么这个 dp 就可以直接使用平衡树维护了,每一次直接在平衡树上二分找到
的位置,然后分左右两侧分别转移。
左边的转移是直接不变就行,右边需要整体加一个等差数列,然后中间需要额外插入一个点。
这个做法是
的,显然太难写了,因为不仅需要区间加等差数列,还需要二分,你还得维护每一个子树的第一个和最后一个节点编号。
所以我们考虑一个稍微好写一点的做法,我们直接去维护相邻两项 dp
的差。
我们设 ,其中
,我们维护 的值。
首先来考虑 怎么找,可以发现
是满足
的最小的 。
而这个条件等价于 ,这个条件可以直接在平衡树上二分。
再写出 的转移式子:
那么我们就能写出
的转移式子
这样我们的平衡树就只需要维护区间加,而不是区间加等差数列了,并且由于这个二分只涉及到一个值,你也不需要记每一个子树的第一个或者最后一个点了,这实在是太牛了。
时间复杂度 。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
| #include<bits/stdc++.h>
#define inf 0x3f3f3f3f3f3f3f3fll
#define debug(x) cerr<<#x<<"="<<x<<endl
using namespace std;
using ll=long long;
using ld=long double;
using pli=pair<ll,int>;
using pi=pair<int,int>;
template<typename A>
using vc=vector<A>;
template<typename A,const int N>
using aya=array<A,N>;
inline int read()
{
int s=0,w=1;char ch;
while((ch=getchar())>'9'||ch<'0') if(ch=='-') w=-1;
while(ch>='0'&&ch<='9') s=s*10+ch-'0',ch=getchar();
return s*w;
}
inline ll lread()
{
ll s=0,w=1;char ch;
while((ch=getchar())>'9'||ch<'0') if(ch=='-') w=-1;
while(ch>='0'&&ch<='9') s=s*10+ch-'0',ch=getchar();
return s*w;
}
mt19937 _rand(time(0)^clock());
struct node
{
ll a,b;
}v[1000005];
int pri[1000005];
ll num[1000005];
ll tag[1000005];
int siz[1000005];
int ls[1000005];
int rs[1000005];
int n,rt,cnt;
inline void T(int p,ll y)
{
num[p]+=y;
tag[p]+=y;
}
inline void push_down(int p)
{
if(ls[p]) T(ls[p],tag[p]);
if(rs[p]) T(rs[p],tag[p]);
tag[p]=0;
}
inline void push_up(int p)
{
siz[p]=siz[ls[p]]+siz[rs[p]]+1;
}
int merge(int u,int v)
{
if(!u||!v) return u|v;
push_down(u),push_down(v);
if(pri[u]>pri[v])
{
rs[u]=merge(rs[u],v);
push_up(u);
return u;
}
else
{
ls[v]=merge(u,ls[v]);
push_up(v);
return v;
}
}
void split(int p,int &x,int &y,ll a,ll b,int bef)
{
if(!p){ x=y=0;return ;}
push_down(p);
if(num[p]<=(bef+siz[ls[p]])*a+b)
{
y=p;
split(ls[p],x,ls[y],a,b,bef);
push_up(y);
}
else
{
x=p;
split(rs[p],rs[x],y,a,b,bef+siz[ls[p]]+1);
push_up(x);
}
}
inline int New(ll v)
{
cnt++;
num[cnt]=v,tag[cnt]=0;
ls[cnt]=rs[cnt]=0;
siz[cnt]=1,pri[cnt]=_rand();
return cnt;
}
ll ans;
void output(int p)
{
if(!p) return ;
push_down(p);
output(ls[p]);
ans+=num[p];printf("%lld\n",ans);
output(rs[p]);
}
int main()
{
n=read();
for(int i=1;i<=n;i++) v[i].a=lread(),v[i].b=lread();
sort(v+1,v+n+1,[](node a,node b){ return a.a<b.a;});
for(int i=1;i<=n;i++)
{
int x,y;
split(rt,x,y,v[i].a,v[i].b,0);
T(y,v[i].a);
rt=merge(x,merge(New(siz[x]*v[i].a+v[i].b),y));
}
output(rt);
return 0;
}
|